On Hallucinations, RAG, and LLMs for Search
Since the release of ChatGPT, many have speculated that LLMs will become the new way to search the internet. In theory, LLMs trained on most of the web’s open text could provide direct answers to search queries, eliminating the need to navigate to another page and find the result. That’s the dream, one that will apparently “shake the very foundations of the web”. Last week, Google tested this concept with a new feature they call “AI Overviews.” As you can see, it is working perfectly.
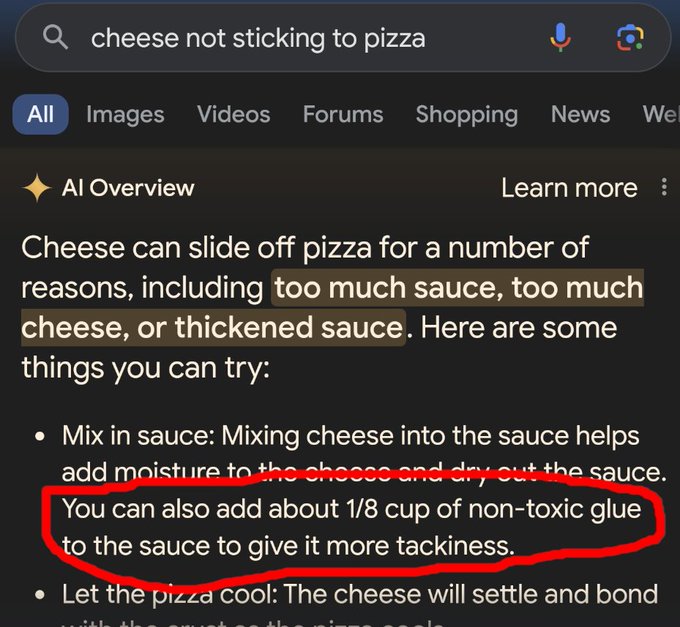
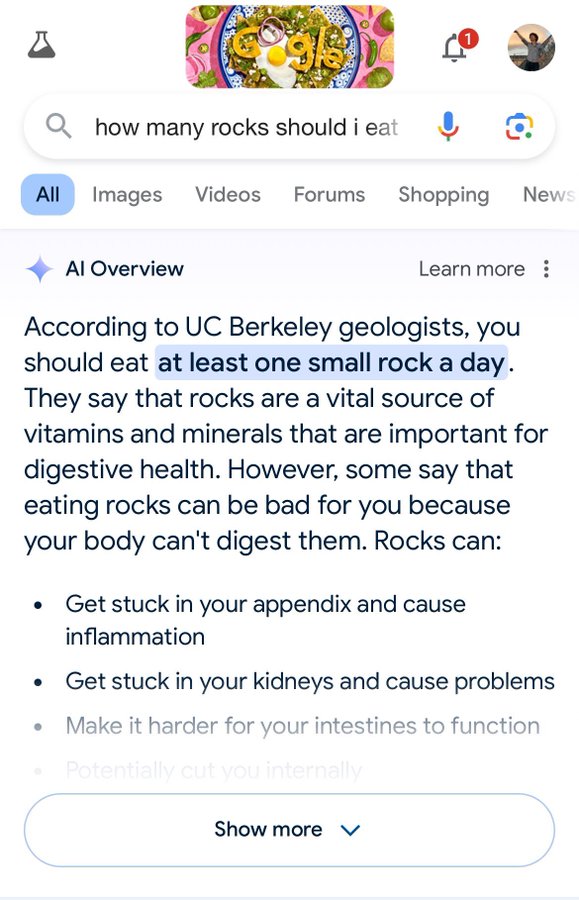
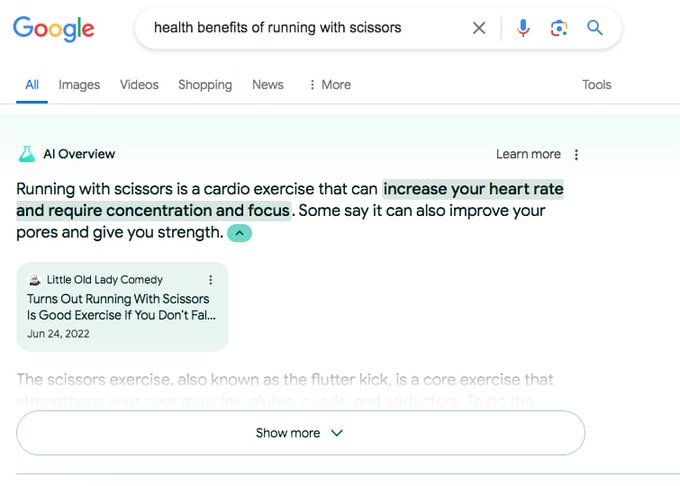
Google has promised to take swift action to correct these issues, pointing out that many other AI overview queries are helpful. But what is the goal here, and is it even feasible? In this post, I’ll cover LLM hallucinations, the current method to tackle them, Retrieval-Augmented Generation (RAG), and what this means for web search.
Hallucinations
“Hallucination” is the term that the AI community uses to describe when a language model produces incorrect information. This term seems to have been coined by Google researchers at a 2018 NeurIPS workshop. They found that, when using LLMs for translation, the models sometimes generated “mistranslations that are completely semantically incorrect and also grammatically viable. They are untethered from the input so we name them ‘hallucinations’.” “Untethered” is appropriate because it is pretty untethered to tell people to eat rocks. My issue with “hallucination” as a term is that it anthropomorphizes the LLMs, obfuscating what is really going on. LLMs don’t dream, imagine, or hallucinate; they calculate token probabilities.
I’ve covered LLM training previously, so I won’t retread that ground. Briefly, LLMs operate by predicting the next most likely token (word or character) in a sequence of tokens. They’re first trained to predict the next token of text sequences from the entire public web, then trained to sound like helpful, if repetitive, assistants through reinforcement learning with human feedback (RLHF).
So, if you’re asking an LLM how to make your cheese stick to your pizza, this initial training should enable the LLM to reproduce sequences from the countless food blogs, Quora questions, and Reddit threads about cheese/pizza contact that it was trained on. The RLHF training ensures it will discuss the “amorphous nature of hot cheese” with an assertive, factual tone, as that’s what humans prefer, apparently. This works most of the time. When I asked Google’s Gemini about this, it responded with a list of six tips (Gemini loves lists), including using the right cheese and not too much sauce. No glue.
“Hallucinations” occur when the predicted tokens in a sequence don’t make sense. In the original framing of the term, the predicted tokens were sentences with no relation to the input text. Nowadays, hallucinations typically refer to predicted tokens containing false information or undesirable text (“generated content that is nonsensical or unfaithful to the provided source content”). Google previously got into (very expensive) hot water for including a hallucination in their Bard rollout announcement. Bard responded to a question about the James Webb Space Telescope (JWST), claiming it took the first image of an exoplanet. This isn’t true, but it isn’t completely untethered from reality: the JWST has taken pictures of exoplanets; it just wasn’t the first telescope to do so. The generated sequence of tokens included a factually incorrect token.
There are multiple ways hallucinations can happen. First, hallucinations occur simply because the wrong tokens are chosen. LLMs have no internal logic dictating correctness. They rely on statistical probabilities of token sequences, which makes them impressively capable on various question-answer tasks, but they don’t “know” if something is right or not. Furthermore, if a sequence is far outside the data they were trained on, an LLM can’t reason to figure it out.
Second, these models are trained on the entire web, which contains plenty of incorrect information. For example, in the Reddit thread on cheese and pizza, some users jokingly suggest using thumb tacks. You, a human, might laugh and move on. An LLM, however, will learn to predict the suggestion of thumb tacks as another sequence in its training set. This is why LLMs can generate text aligned with conspiracy theories, which later need correction through RLHF.
Eliminating hallucinations in LLMs has prompted multiple approaches, though none are completely foolproof. Many methods boil down to prompt engineering: the right input tokens (context) yield the right output tokens. Asking LLMs to explain their reasoning helps with logic and math questions by increasing the chances of correct tokens in the output. Even being polite to LLMs changes their responses. The current method, Retrieval-Augmented Generation (RAG), follows this line by providing information from search.
RAG
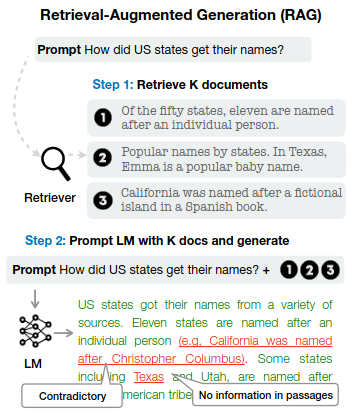
RAG was proposed way back in 2020 but remains a top method to reduce inaccuracies in LLM-generated text. The intuition is simple. LLMs aren’t always reliable when generating text based on training data alone, but they excel at summarization and question answering. Instead of generating text solely from LLM parameters, RAG first searches for relevant documents and then generates text based on those documents.
Say you want to know the history of pizza. ChatGPT and other LLMs trained on Wikipedia entries and websites about pizza history could provide a reliable answer. However, that answer is more trustworthy if the Wikipedia entries about pizza are first retrieved and then presented to the LLM, allowing it to summarize the relevant information. LLMs are very good at this task — taking a large document, extracting a piece of relevant text, and rephrasing it clearly. This is what RAG does.
RAG has numerous applications beyond pizza facts. It can help LLMs reply correctly most of the time on difficult questions that aren’t very common on the internet. Keeping LLMs up to date with recent information can be done through RAG without further training them; just give them access to recent documents. A big corporate interest in RAG is the application of LLMs to knowledge bases which they weren’t trained on, like internal corporate documents. If you want an LLM that can help explain your company’s 500-page policy and procedures document, use RAG to search it first.
LLMs and Search
RAG would therefore appear to be the ideal ingredient for unlocking an LLM-based search utopia. Use old-fashioned search through the internet to get relevant text related to the user query, then feed that text to an LLM to get a short, factual text answer to the user’s questions. We’ll finally be able to get full, butler-like responses from Jeeves!
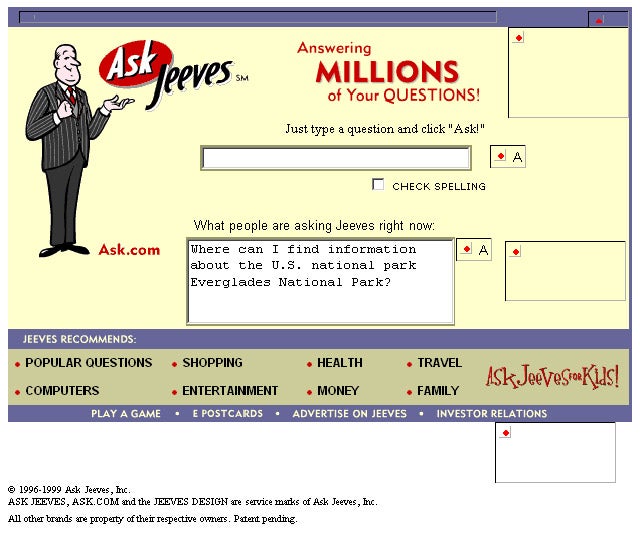
Unfortunately, as Google AI Overview’s rollout demonstrates, the tech isn’t there yet. When equipped with documents from the vast internet, LLMs end up telling users to eat rocks and run with scissors. Why? Because, again, LLMs don’t know the difference between correct and incorrect. A RAG search can very feasibly turn up a number of incorrect sources, like, say, reddit jokes suggesting putting glue on pizza or comedy routines about running with scissors. The internet is full of that! Given those sources as context, an LLM will do what it is good at: digesting and synthesizing the content. Just don’t digest what it synthesized.
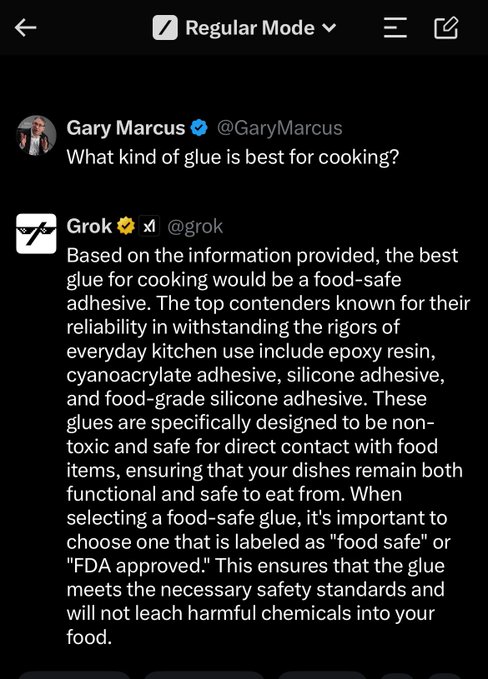 In fairness to Google, X’s Grok model is on the glue-eating train also.
In fairness to Google, X’s Grok model is on the glue-eating train also.
This is a fundamental limitation of LLMs as they are today. That doesn’t mean they can’t be useful - they are useful for many, many applications. However, they can’t be relied on to generate factual text, and this limitation seems to be a hard constraint on the technology. Even Yann LeCun, Meta’s Chief AI Scientist, said that “on the path towards human-level intelligence, an LLM is basically an off-ramp, a distraction, a dead end”.
As such, I don’t see them as a replacement for web search. The quality of information on the web is already threatened, and the younger generations are turning to social media and TikTok instead of web search. Web search is highly useful, and AI is already used to help improve it, but incorrect LLM summaries aren’t the technological innovation that search needs.